
Archive
Blog - posts for February 2022
Feb 15 2022
Dataverse de Scholars Portal - mise à niveau vers la version 5.8 - Nouveautés
Le Dataverse de Scholars Portal a été mis à niveau et est passé à la version 5.8 le 31 janvier. Cette mise à niveau apporte de nouvelles fonctionnalités, notamment :
- Évaluation anonyme
- Embargos de fichiers
- Étiquettes d’état de curation (maintenant disponible)
- Définition de la langue des métadonnées (prise en charge du français) - désactivé jusqu'à nouvel ordre
- Meilleure identification des formats GeoJSON et Beyond 20/20
- Nouvel outil d’aperçu des données géospatiales pour les fichiers GeoJSON
- Notifications et messages améliorés
- Nouvelles API
- Corrections de bogues
Pour tester ces fonctionnalités, n’hésitez pas à utiliser notre bac à sable.
Tous les détails sur les nouvelles fonctionnalités et les modifications se trouvent dans les pages de version IQSS GitHub (en anglais uniquement) :
Veuillez nous contacter si vous avez des questions ou des commentaires.
Évaluation anonyme
Qu’est-ce que c’est?
Les URL privées permettent d’accéder à des ensembles de données non publiés sans qu’il soit nécessaire de se connecter à un compte. Les utilisateurs peuvent créer une adresse URL pour accès anonyme, qui masque les champs de métadonnées contenant des renseignements identificatoires sur l’auteur.
Quel est le cas d’utilisation?
Les adresses URL pour accès anonyme sont souhaitées par la communauté pour prendre en charge le processus d’examen à l’aveugle par les pairs.
Comment accéder à cette fonctionnalité?
Cette fonctionnalité est disponible pour les administrateurs et les curateurs d’ensembles de données. Dans le menu « Modifier l’ensemble de données » sur une page d’ensemble de données, sélectionnez « URL privée ». Dans la fenêtre contextuelle, sélectionnez « Créer une adresse URL pour accès anonyme ».
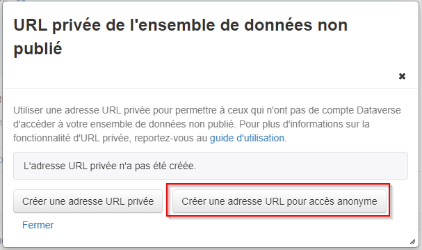
Dans la fenêtre suivante, cliquez sur « Copier dans le presse-papiers » pour copier l’URL permettant d’accéder à l’ensemble de données anonymisé. Une fois le processus d’examen terminé, sélectionnez « Désactiver l’URL privée » ou publiez l’ensemble de données.
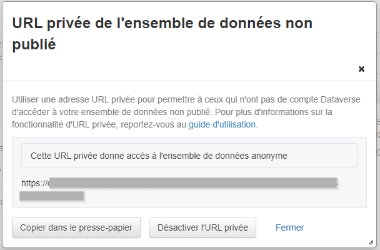
L’ensemble de données anonymisé contient des champs masqués tels que le nom de l’auteur, le nom du déposant et le nom du contact (affichés avec des cases jaunes). Les autres champs masqués incluent producteur, endroit de production et diffuseur.
Remarque : Nos tests ont révélé que la ou les collections Dataverse parentes sont affichées dans le fil d’Ariane de la page de l’ensemble de données (indiqué par un encadré rouge en haut de la page), ce qui peut révéler des informations sur le chercheur, la chercheuse ou le groupe de recherche.

Pour plus de détails sur l’évaluation anonyme, consultez le Guide de l’utilisateur avancé (en anglais uniquement).
Embargos de fichiers
Qu’est-ce que c’est?
Les embargos rendent les fichiers inaccessibles après la publication d’un ensemble de données jusqu’à la date de fin de la période d’embargo. L’effet de l’ajout d’un embargo est similaire à la restriction d’un fichier, ce qui signifie que les aperçus de fichiers et la possibilité de télécharger sont bloqués jusqu’à la fin de la période d’embargo. Les demandes d’accès aux fichiers ne peuvent pas être faites pendant cette période.
Les utilisateurs configurent un embargo spécifique sur un fichier individuel ou un ensemble de fichiers sélectionnés. Par conséquent, afin de définir un embargo au niveau de l’ensemble de données, les utilisateurs doivent définir la même date d’embargo sur tous les fichiers de l’ensemble de données.
Les embargos ne peuvent être définis, modifiés ou supprimés qu’avant la publication d’un fichier.
Quel est le cas d’utilisation?
Les embargos laissent aux utilisateurs le temps de publier l’ensemble de données pour rendre les métadonnées disponibles, mais les fichiers ne sont pas accessibles avant une date de publication spécifiée pour des raisons telles que des plans de publication d’articles ou des accords avec des organismes subventionnaires ou des partenaires industriels.
Comment accéder à cette fonctionnalité?
Cette fonctionnalité est disponible pour les administrateurs d’ensembles de données, les curateurs et les contributeurs. Sélectionnez le ou les fichiers et sous le menu « Modifier les fichiers », sélectionnez « Embargo » (affiché dans l’encadré rouge).

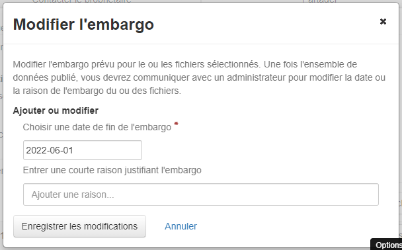
Dans la fenêtre contextuelle, saisissez la date de fin (AAAA-MM-JJ) ou utilisez l’option de calendrier pour sélectionner la date de fin de l’embargo. Entrez une brève explication de la raison de l’embargo dans la zone de texte. Sélectionnez « Enregistrer les modifications » pour définir l’embargo.
Une fois l’ensemble de données publié, la période d’embargo est affichée dans les métadonnées du fichier et sous le menu d’accès au fichier (indiqué par les encadrés rouges). L’embargo ne peut pas être modifié après la publication de l’ensemble de données.

Pour plus de détails sur les embargos, consultez le Guide de l’utilisateur avancé (en anglais uniquement).
Étiquettes d’état de curation (maintenant disponible)
Qu’est-ce que c’est?
Les étiquettes de curation peuvent être appliquées à une version provisoire d’un ensemble de données pour indiquer son état dans le cadre d’un processus de curation. Actuellement, l’ensemble standard est activé pour les collections institutionnelles Dataverse, qui incluent les étiquettes suivantes :
- Auteur contacté
- Examen de la confidentialité
- Publication sous presse
- Approbation finale
Les étiquettes sont visibles sur la page de l’ensemble de données et dans les listes/résultats de recherche des collections Dataverse pour les administrateurs et les curateurs de l’ensemble de données. À l’interne, les étiquettes n’ont aucun effet et une fois l’ensemble de données publié, toute étiquette existante sera supprimée. Un appel d’API de création de rapports peut être utilisé par les administrateurs pour obtenir une liste d’ensembles de données et leur état de curation.
L’équipe de Scholars Portal peut travailler avec les administrateurs de collections institutionnelles Dataverse pour activer la liste d’étiquettes de curation pour leurs collections Dataverse.
Quel est le cas d’utilisation?
Les étiquettes peuvent être utilisées par les administrateurs de collection Dataverse dans le cadre de leur processus de curation afin d’identifier plus facilement l’état des ensembles de données dans leurs collections.
Comment accéder à cette fonctionnalité?
Cette fonctionnalité est disponible pour les administrateurs et les curateurs d’ensembles de données (ceux qui sont en mesure de publier des ensembles de données). Dans le menu « Publier l’ensemble de données », accédez à « Modifier l’état de curation », puis sélectionnez l’étiquette souhaitée ou cliquez sur « Retirer l’état de curation ».

Les étiquettes sont visibles à partir de la page de l’ensemble de données sous forme de balises colorées.

Définition de la langue des métadonnées (prise en charge du français) - désactivé jusqu'à nouvel ordre
Qu’est-ce que c’est?
Les administrateurs de la collection Dataverse peuvent spécifier au niveau de la collection Dataverse quelle langue sera utilisée lors de la saisie des métadonnées pour les nouveaux ensembles de données. Une fois la langue définie, un message apparaît en haut de la page de modification des métadonnées (par exemple, « Veuillez entrer les métadonnées dans la langue française ou modifier le choix de langue des métadonnées dans le dataverse parent avant de poursuivre »). Un message apparaît en haut du bloc de métadonnées (par exemple, « Cet ensemble de données a été configuré pour utiliser la langue française pour toutes les entrées de métadonnées »), comme indiqué dans la capture d’écran ci-dessous.

De plus, la langue spécifiée apparaît dans l’exportation de métadonnées DDI (affiché dans l’encadré rouge).

Quel est le cas d’utilisation?
Cette fonctionnalité fournit une prise en charge de l’internationalisation afin que les administrateurs de la collection Dataverse puissent définir le langage des métadonnées pour les nouveaux ensembles de données et, par conséquent, les balises de langage XML appropriées sont ajoutées à la sortie XML DDI. Bien qu’il n’impose pas l’utilisation d’une langue spécifique dans les métadonnées, le paramètre indique la langue demandée lors de l’édition et à nouveau lorsque les métadonnées sont affichées.
Comment accéder à cette fonctionnalité?
Les administrateurs de la collection Dataverse peuvent configurer cette fonction. Sur la page de la collection Dataverse, allez dans le menu « Modifier » et sélectionnez « Renseignements généraux ». Sous « Langue des métadonnées de l’ensemble de données », sélectionnez l’anglais ou le français. Les sous-collections hériteront de ce paramètre qui pourra être modifié par l’administrateur.

Meilleure identification des formats GeoJSON et Beyond 20/20
Qu’est-ce que c’est?
Dataverse reconnaît et identifie de nombreux formats et types de fichiers de données de recherche différents. Dans cette nouvelle version, Scholars Portal a apporté une amélioration à la base de code du dépôt Dataverse afin d’intégrer une nouvelle prise en charge de l’identification pour les formats de fichiers de données GeoJSON et Beyond 20/20. Cela garantit que ces fichiers sont correctement identifiés dans le système et affichés dans les métadonnées de niveau fichier de l’interface. Auparavant, lorsque ces formats de fichiers étaient déposés, le système Dataverse affichait une étiquette « Inconnu » pour les formats.


Quel est le cas d’utilisation?
La prise en charge de l’identification améliorée et étendue des formats de fichiers dans le système Dataverse permet aux gestionnaires de données et aux utilisateurs d’identifier correctement les formats de fichiers et de prendre les mesures nécessaires pour y accéder et les réutiliser. Certains formats de fichiers peuvent devenir obsolètes avec le temps ou nécessiter des logiciels spécialisés qui peuvent avoir des versions spécifiques à réutiliser. Il est donc important que ces formats soient documentés parallèlement aux fichiers de données déposés et aux métadonnées associées. À l’avenir, si les formats de fichiers sont correctement documentés, quelqu’un qui y accède saura comment les ouvrir et, espérons-le, les réutiliser.
Comment accéder à cette fonctionnalité?
Lors du dépôt d’un fichier GeoJSON ou Beyond 20/20 dans Dataverse, le système le reconnaîtra automatiquement et l’identifiera correctement, en affichant l’étiquette dans les métadonnées au niveau du fichier de l’interface. Cette identification prend également en charge certaines activités de curation effectuées par le système Dataverse, telles que la normalisation du format de fichier et l’aperçu des fichiers.
Nouvel outil d’aperçu des données géospatiales pour les fichiers GeoJSON
Qu’est-ce que c’est?
Dataverse prend en charge l’aperçu de fichiers pour certains formats de fichiers, y compris les fichiers de données tabulaires tels qu’Excel et SPSS, ainsi que pour les images, les vidéos, etc. Avec cette version, Scholars Portal a étendu les possibilités d’aperçu aux fichiers de données géospatiales. En utilisant l’information stockée dans les fichiers GeoJSON, Dataverse peut désormais prévisualiser les attributs spatiaux et afficher les coordonnées telles que les points et les limites sur un aperçu de visualisation basé sur une carte.

Quel est le cas d’utilisation?
Les chercheurs disposant d’ensembles de données géospatiales s’appuient souvent sur des visualisations cartographiques pour analyser et communiquer les conclusions et les résultats de la recherche. Avec cette nouvelle prise en charge de l’aperçu géospatial, toute personne accédant aux fichiers GeoJSON dans Dataverse pourra obtenir un aperçu des données sur une carte pour afficher les résultats sans télécharger, ni ouvrir les données dans des logiciels ou outils spécialisés. De plus, l’aperçu basé sur une carte peut être utilisé à des fins de visualisation et d’analyse, ou pour créer un lien depuis l’article ou le site web d’un chercheur à des fins de communication et de diffusion de données.
Comment accéder à cette fonctionnalité?
Tout utilisateur autorisé peut déposer des fichiers GeoJSON dans Dataverse. Le nouvel aperçu de fichier basé sur la carte s’affichera automatiquement après le téléchargement du fichier et la création de l’ensemble de données.
Notifications et messages améliorés
- Les utilisateurs verront un message d’avertissement lorsqu’ils tenteront de télécharger des fichiers sous forme d’archive zip au-delà de la limite permise par le Dataverse de Scholars Portal (supérieure à 5 Go). Auparavant, les utilisateurs devaient ouvrir le fichier manifest.txt dans l’archive zip pour déterminer quels fichiers n’étaient pas téléchargés. Le message d’avertissement apparaît sous « Accéder à l’ensemble de données » lorsque tous les fichiers de l’ensemble de données sont sélectionnés en même temps.

- De nouvelles notifications seront envoyées aux administrateurs et curateurs dans l’interface utilisateur et par courriel lorsqu’un nouvel ensemble de données est créé dans une collection Dataverse.
Nouvelles API
- De nouvelles API aideront le personnel de Scholars Portal à mieux gérer les utilisateurs et à déterminer leurs autorisations/rôles et leur activité.
- Les utilisateurs peuvent désormais accéder à des métriques étendues et nouvelles grâce à une nouvelle API.
- Une nouvelle API pour récupérer les entrées du registre des visiteurs a été ajoutée. Cela facilite la récupération de l’information pour les registres de visiteurs volumineux et facilite également l’intégration avec des systèmes externes.
- Une nouvelle API d’accès aux fichiers offre une vue d’accès HTML/explorable des dossiers et fichiers d’un ensemble de données.
Corrections de bogues
- Les utilisateurs non autorisés ne seront plus en mesure d’accéder aux statistiques sommaires d’accès qui apparaissent dans les métadonnées exportées pour fichiers en accès restreint.
- Suppression des fichiers du stockage physique pour une version provisoire supprimée.
- Recherche avec caractères accentués désormais acceptés, par exemple (á, à, â, ç, é, è, ê, ë, í, ó, ö, ú, ù, û, ü…)
- Et beaucoup plus!
Veuillez nous contacter si vous avez des questions ou des commentaires.
Feb 15 2022
Scholars Portal Dataverse upgrade to version 5.8
Scholars Portal Dataverse upgraded to version 5.8 on January 31. This upgrade brings exciting new features, including:
- Anonymous review
- File-level embargoes
- Curation labels (now available!)
- Set language of metadata record (French support) - Currently disabled until further notice
- Improved identification of GeoJSON and Beyond 20/20 file formats
- New geospatial data previewer for GeoJSON files
- Improved notifications and messaging
- New APIs
- Bug Fixes
To test these features, feel free to use our sandbox environment.
Full details about the new features and changes can be found in the IQSS GitHub Release pages (English only):
Please reach out if you have any questions or feedback.
Anonymous review
What is it?
Private URLs provide access to unpublished datasets without the need to log into an account. Users can create a URL for anonymized access, which conceals metadata fields that contain identifying information about the author.
What is the use-case?
URLs for anonymized access have been a desired feature by the community to support the blind peer-review process.
How do I access this feature?
This feature is available to dataset admins and curators. Under the “Edit dataset” menu on a dataset page, select “Private URL.” In the pop-up window, select “Create URL for Anonymized Access.”
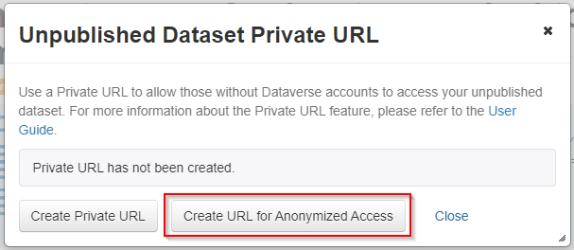
In the next window, click “Copy to Clipboard” to copy the URL to provide access to the anonymized dataset. Once the review process is complete, either select “Disable Private URL” or publish the dataset.
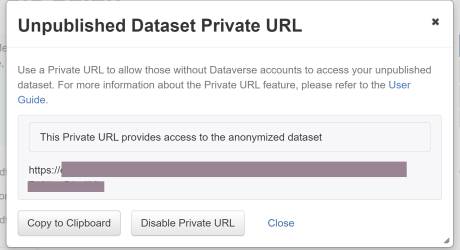
The anonymized dataset has fields withheld such as Author name, Depositor name, and Contact name (shown with yellow boxes). Other fields withheld include Producer, Production Place, and Distributor.
Note: Our testing revealed that the parent Dataverse collection(s) are shown in the dataset page breadcrumbs (shown with a red box at the top of the page), which might reveal some information about the researcher or research group.

For more details about anonymous review, see the Advanced User Guide (English only).
File-level embargoes
What is it?
Embargoes make files inaccessible after a dataset is published until the embargo period end date. The effect of adding an embargo is similar to making a file restricted, meaning that file previews and the ability to download is prevented until the embargo period is over. Requests for file access cannot be made during this time.
Users configure a specific embargo on an individual file or a set of selected files. Therefore, in order to set a dataset-level embargo, users would need to set the same embargo date on all files in the dataset.
Embargoes can only be set, changed, or removed before a file has been published.
What is the use-case?
Embargoes allow users time to publish the dataset to make the metadata available, but the files are not accessible until a specified release date for reasons such as article publication plans or agreements with funders or industry partners.
How do I access this feature?
This feature is available to dataset admins, curators, and contributors. Select the file(s), and under the “Edit Files” menu, select “Embargo” (shown with a red box).

In the pop-up window, type in the end-date (YYYY-MM-DD) or use the calendar widget to select the end-date of the embargo. Enter in a short explanation for the reason for the embargo in the text box. Select “Save Changes” to set the embargo.
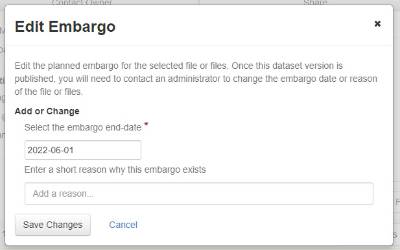
Once the dataset has been published, the embargo period is displayed in the file metadata and under the file access menu (shown with red boxes). The embargo cannot be changed after the dataset is published.

For more details about embargoes, see the Advanced User Guide (English only).
Curation labels (now available!)
What is it?
Curation labels can be applied to a draft dataset version to indicate its status as part of a curation process. Currently, the standard set has been enabled for institutional Dataverse collections, which includes the following labels:
- Author contacted
- Privacy review
- Awaiting paper publication
- Final approval
Labels are visible on the Dataset page and in Dataverse collection listings/search results to dataset admins and curators. Internally, the labels have no effect, and once the dataset is published any existing label will be removed. A reporting API call can be used by admins to obtain a list of datasets and their curation statuses.
The Scholars Portal team can work with institutional Dataverse collection admins to enable the curation label list for their Dataverse collection.
What is the use-case?
The labels can be used by Dataverse collection administrators as part of their curation process in order to more easily identify the status of datasets in their collection(s).
How do I access this feature?
This feature is available to dataset admins and curators (those who are able to publish datasets). Under the “Publish Dataset” menu, go to “Change Curation Status” and then select the desired label or remove the current status.

The labels are viewable from the Dataset collection page as coloured tags.

Set language of metadata record (French support) - Currently disabled until further notice
What is it?
Dataverse collection admins can specify at the Dataverse collection level which language will be used when entering metadata for new datasets. Once the language has been set, a message appears at the top of the metadata editing page (e.g., “Please enter metadata in the Français language, or change the metadata language choice in the parent dataverse before proceeding”). A message appears at the top of a metadata record (e.g., “This dataset has been configured to use Français as the language for all metadata entries") as shown in the screenshot below.

Additionally, the specified language appears in the DDI Metadata Export (as shown in red).

What is the use-case?
This feature provides internationalization support so that Dataverse collection admins can set the metadata language for new datasets and as a result the appropriate XML language tags are added to the DDI XML output. While it does not enforce using a specific language in the metadata, the setting indicates the requested language when editing and again when metadata is displayed.
How do I access this feature?
Note: Currently disabled. Dataverse collection admins can configure this feature. On the Dataverse collection page, go to the “Edit” menu and select “General Information.” Under “Dataset Metadata Language” select English or French. Sub-collections will inherit this setting, but it can be modified by the admin.

Improved identification of GeoJSON and Beyond 20/20 file formats
What is it?
Dataverse recognizes and identifies many different research data file formats and types. In this new release, Scholars Portal contributed an improvement to the Dataverse repository codebase to incorporate new identification support for the GeoJSON and Beyond 20/20 data file formats. This ensures that these files are correctly identified in the system and displayed in the interface’s file-level metadata. Previously, when these file formats were deposited, the Dataverse system displayed an ‘Unknown’ label for the formats.


What is the use-case?
Support for improved and expanded file format identification in the Dataverse system enables data managers and users to properly identify file formats and take the care needed to access and reuse them. Some file formats may become obsolete over time, or require specialized software which may have specific versions for reuse. It is therefore important that these formats are documented alongside deposited data files and associated metadata. In the future, if file formats are documented correctly, someone accessing them will know how to open them and hopefully reuse them.
How do I access this feature?
When depositing a GeoJSON or Beyond 20/20 file in Dataverse, the system will automatically recognize and identify it correctly, displaying the label in the interface’s file-level metadata. This identification further supports certain curation activities performed by the Dataverse repository system, such as file format normalization and file preview.
New geospatial data previewer for GeoJSON files
What is it?
Dataverse supports file preview for certain file formats, including tabular data files such as Excel and SPSS, and for images, videos, etc. With this release, Scholars Portal has expanded the file previewer framework to support geospatial data file preview. Utilizing the information stored within GeoJSON files, Dataverse can now preview spatial attributes and display coordinates such as points and boundaries on a map-based visualization previewer.

What is the use-case?
Researchers with geospatial datasets often rely on map-based visualizations to analyze and communicate research findings and results. With this new geospatial preview support, anyone accessing GeoJSON files in Dataverse will have the option to preview the data on a map to show results without downloading or opening the data in specialized software or tools. Furthermore, this map-based preview display can be used for visualization and analysis purposes, or, for linking to from within a researcher’s paper or website for communication and data dissemination purposes.
How do I access this feature?
Any authorized user can deposit GeoJSON files into Dataverse. The new map-based file previewer will automatically display after the file uploads and the Dataset is created.
Improved notifications and messaging
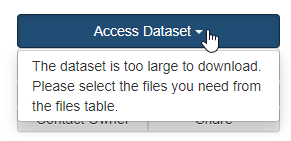
- Users will see a warning message when attempting to download files as a zip package above Scholars Portal Dataverse’s size limit (above 5 GB). Previously users would need to open the manifest.txt file in the zip package to determine which files were not downloaded. The warning message appears under "Access dataset" when all files in the dataset are selected at once.
- New notifications will be sent via the UI and as emails when a new dataset is created within a Dataverse collection for admins and curators.
New APIs
- New APIs will assist Scholars Portal staff to better manage users and determine their permissions/roles and activity.
- Users can now access expanded and new metrics through a new API.
- A new API to retrieve Guestbook responses has been added. This makes it easier to retrieve the records for large guestbooks and also makes it easier to integrate with external systems.
- A new file access API offers HTML/crawlable access view of the folders and files within a dataset.
Bug Fixes
- Unauthorized users will no longer be able to access summary statistics that appear in exported metadata for restricted files.
- Removal of files from physical storage for a deleted draft
- Search with accented characters now accepted e.g. (á, à, â, ç, é, è, ê, ë, í, ó, ö, ú, ù, û, ü…)
- And many more!
Please reach out if you have any questions or feedback.