
Blog
Feb 06 2020
Introducing the Data Curation Tool
The Scholars Portal Dataverse team has been hard at work on the new Dataverse Data Curation Tool as part of our Canarie RDM grant project. Development on this project is being led by Victoria Lubitch, Programmer/Analyst at Scholars Portal.
The Data Curation Tool (DCT) allows data owners and curators to create and edit variable-level metadata for any tabular file in a dataset. Users can access this tool as a modular application once they’ve uploaded a tabular file (e.g., SPSS, R, Excel, CSV) to a dataset in Dataverse.

The Data Curation Tool
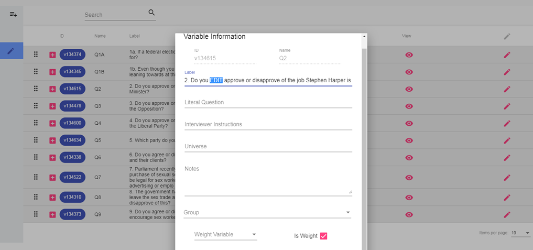
Similar to tools like SPSS, the DCT allows users to view summary statistics about their data, add variable information like 'Interviewer Instructions' or 'Notes', create variable groups, and indicate weighting variables.

Summary statistics in the DCT

Variable editor in the DCT
Once edits have been completed and saved back to Dataverse, these changes can then be downloaded as an XML file or exported to a codebook.

Example of a codebook in Dataverse
Usability testing sessions were recently completed with 5 participants, who worked through a series of tasks and helped us identify areas where the user experience could be improved in the tool. We’re now working on translating this tool to be used in French, with translations provided by the University of Ottawa.
A demo of this tool is available online, and the code can be accessed on GitHub. The Data Curation Tool will be launched with the next Scholars Portal Dataverse upgrade, currently scheduled for the end of October, and will be available for community testing soon.
If you have any comments or suggestions, contact us at dataverse@scholarsportal.info. If you would like to see all the updates and have a SpotDocs account, click the "Watch this blog" button on the top right corner of the page to receive notifications.
Jul 09 2019
CANARIE project update: Dataverse for the Canadian Research Community
Background
Welcome to our Scholars Portal Dataverse blog, where we will be sharing news and updates about the Dataverse platform and service, including development work. Our first blog post provides an update about the development project "Dataverse for the Canadian Research Community"! This project is funded by CANARIE's RDM grant program and led by Scholars Portal and University of Toronto Libraries, with support from CARL and Portage.
We're currently about half way through our 18 months of development work (October 2018-March 2020).
The aim of the grant is to enhance Dataverse to address the needs of a broad range of researchers in Canada through improved scalability, improved integrations with Canadian cloud storage and authentication providers, and better support for data curation workflows. These three areas of development are described further below and will be discussed in more detail in future blog posts.
Scalability | The goals of the first leg of the project include:
Planned deliverables:
|
|
Authentication | The goals of the second leg of the project include:
Planned deliverables:
|
|
Data Curation | The goals of the third leg of the project include:
Planned deliverables:
|
|
Status update
Our Project Timeline & Deliverables roadmap is included below. We have completed our first two deliverables and are currently working on the third.
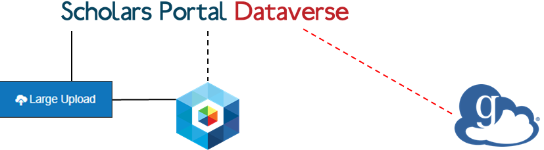
For our first deliverable to connect Dataverse with Swift as the primary storage service, we stood up a test instance of Dataverse connected to the OLRC. The SP team tested upload and download functionality, as well as the integrity of files stored, with a variety of file types and sizes, along with other functionalities core to Dataverse. The idea behind this type of configuration would allow us to more easily scale the system, add storage resources, and run the platform more optimally.
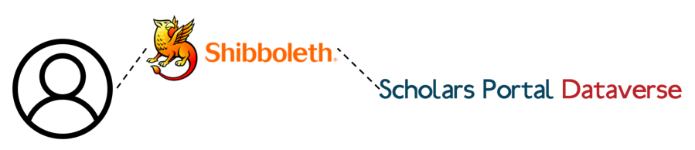
We have also successfully configured Dataverse to work with Shibboleth for single sign-on using the University of Toronto as the test case. We are now initiating a pilot project with interested institutions to test out new sign-up and login workflows. More details to come in another blog post.
Currently, we are working on completing our third deliverable - developing the Data Curation Tool. We presented the DCT prototype at NADDI (link to slides) and at the Dataverse Community Meeting (link to slides). Feel free to test out the Data Curation Tool - Prototype and stay tuned for a future blog post describing the development of this tool.
In the fall, we will start to focus on the large-file support and storage connection pieces of the project.
We will be sharing more details about these deliverables and details about the development work in upcoming blog posts! If you have any comments or suggestions, please feel free to contact us at dataverse@scholarsportal.info. If you would like to see all the updates and have a Spotdocs account, click the "Watch this blog" button on the top right corner of the page to receive notifications.
Project Timeline & Deliverables
